지난 포스팅에서 안드로이드 스튜디오를 업데이트하고 플러터 플러그인을 설치해보았습니다. 추가된 플러그인을 통해 샘플 프로젝트를 만들고 실행을 해보았지만 예상대로 문제가 발생했고, 안드로이드 가상 장치에서 시험을 해볼 수 없었습니다. 무슨 문제가 있었던 것일까요?
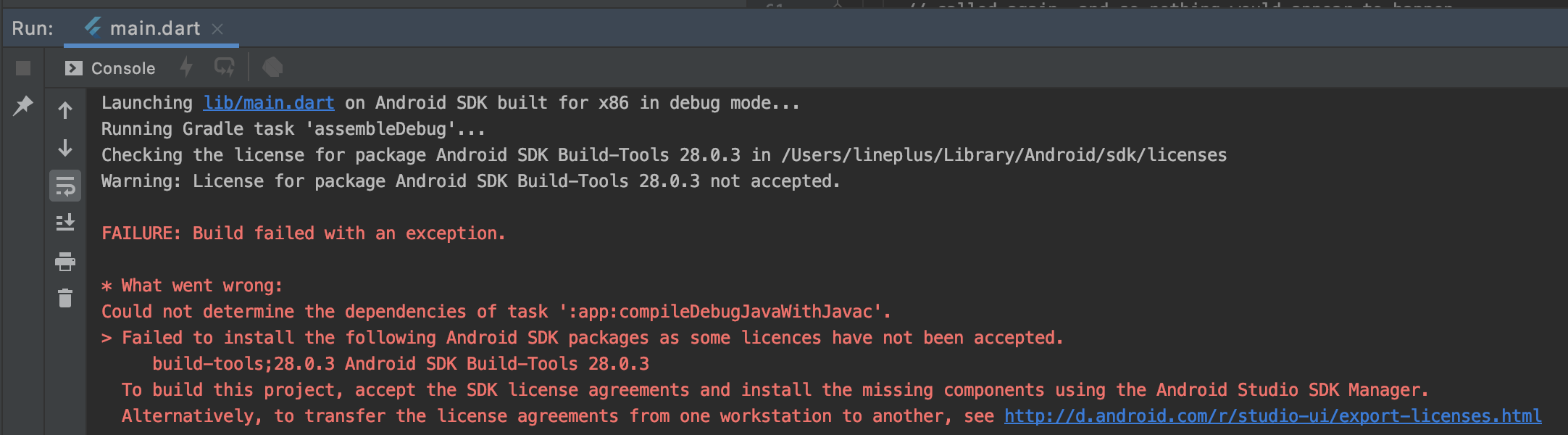
안드로이드 스튜디오에서 플러터 프로젝트를 생성하고 기본 샘플 앱을 가상 안드로이드 기기로 실행했을때 발생한 에러 화면입니다. 뭔가 SDK와 관련된 라이센스가 제대로 적용이 안된 것 같은 에러메세지입니다. 바로 터미널을 실행하여 플러터 닥터 flutter docter 명령을 통해 문제점을 확인해 보았습니다. 명령은 터미널에서 flutter docter 를 입력하여 수행합니다.
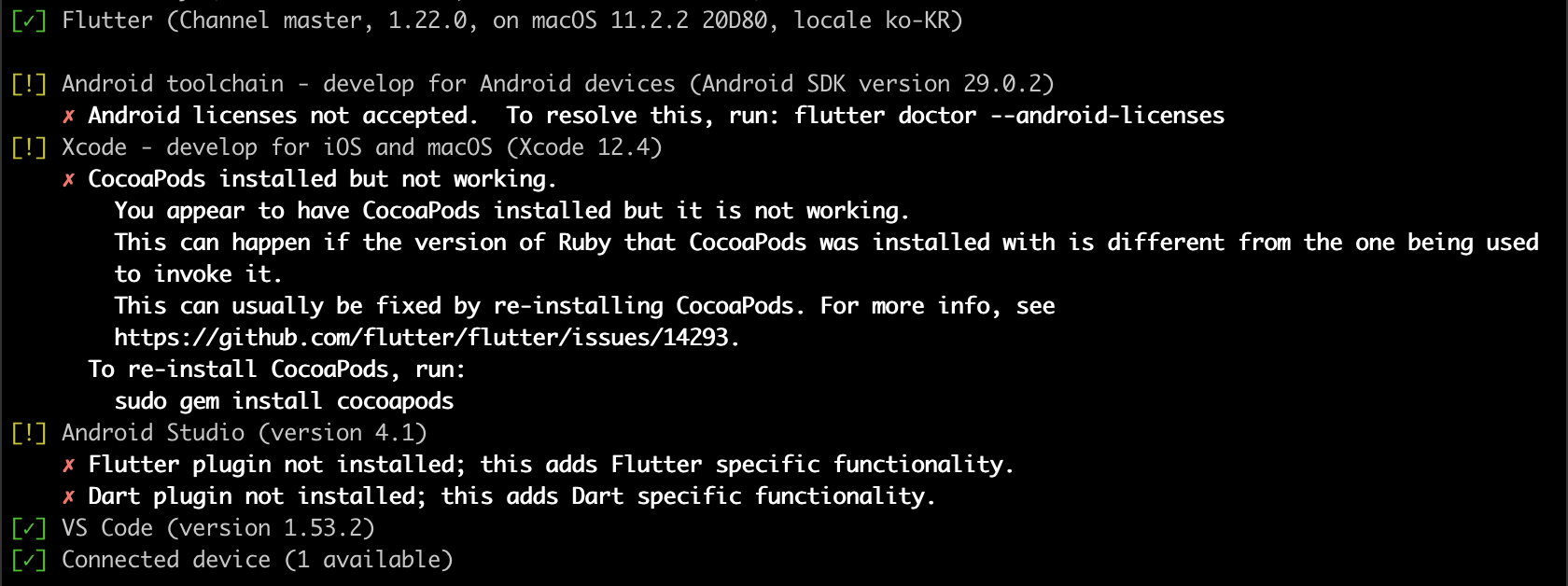
초록색 체크표시가 된 것들은 문제가 없는 부분들입니다. 느낌표로 출력된 내용을 보니 비주얼 스튜디오 코드를 위한 플러터 환경 구성 이후 변경된 것들이 좀 있어 보입니다. 가장먼저 Android toolchain 항목에 대한 명령을 통해 첫번째 문제를 해결해 보겠습니다.
flutter doctor --android-licenses
위의 플러터 닥터 명령은 동의해야 하는 약관, 라이센스에 대한 확인을 해주는 명령입니다. 실행후 나오는 내용을 살펴보고 (영어입니다 -_-;) 동의한다는 의미로 y 키를 몇 번 눌러주면 됩니다. 다시 닥터를 실행해서 처리가 잘 되었는지 보겠습니다.
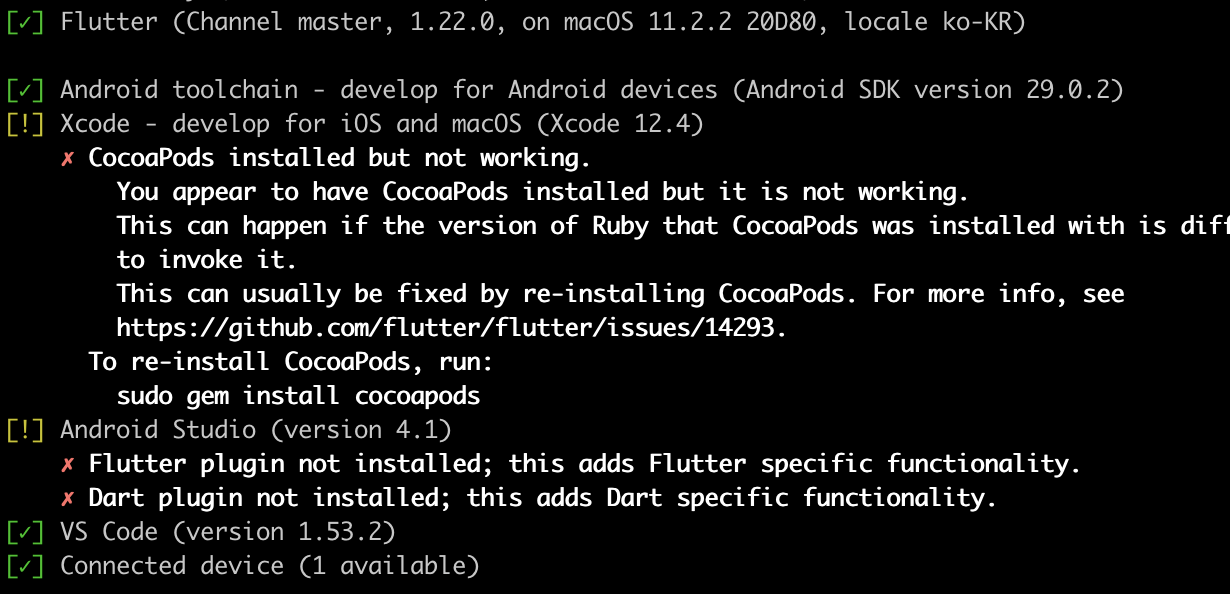
오호라. 첫번째 Android toolchain 항목도 이제 초록색 체크로 바뀌었습니다. 플러터로 개발된 코드를 iOS 에서 실행할 수 있도록 하기 위해서는 Xcode 환경도 준비가 되어 있어야 합니다. 지난번에도 CocoaPods 설치하느라 고생했는데... 그래도 다시 한 번 해보았습니다.
# sudo gem install cocoapods
Password:
Fetching i18n-1.8.9.gem
Fetching tzinfo-1.2.9.gem
Fetching activesupport-5.2.4.5.gem
Fetching nap-1.1.0.gem
Fetching fuzzy_match-2.0.4.gem
Fetching concurrent-ruby-1.1.8.gem
...
...
Parsing documentation for gh_inspector-1.1.3
Installing ri documentation for gh_inspector-1.1.3
Parsing documentation for ruby-macho-1.4.0
Installing ri documentation for ruby-macho-1.4.0
Parsing documentation for cocoapods-1.10.1
Installing ri documentation for cocoapods-1.10.1
Done installing documentation for concurrent-ruby, i18n, thread_safe, tzinfo, activesupport, nap, fuzzy_match, httpclient, algoliasearch, ffi, ethon, typhoeus, netrc, public_suffix, addressable, cocoapods-core, claide, cocoapods-deintegrate, cocoapods-downloader, cocoapods-plugins, cocoapods-search, cocoapods-trunk, cocoapods-try, molinillo, atomos, CFPropertyList, colored2, nanaimo, xcodeproj, escape, fourflusher, gh_inspector, ruby-macho, cocoapods after 25 seconds
34 gems installed
자, 코코아포드 관련한 패키지들의 추가도 끝났으니 다시 flutter docter 를 실행해 봐야겠죠?
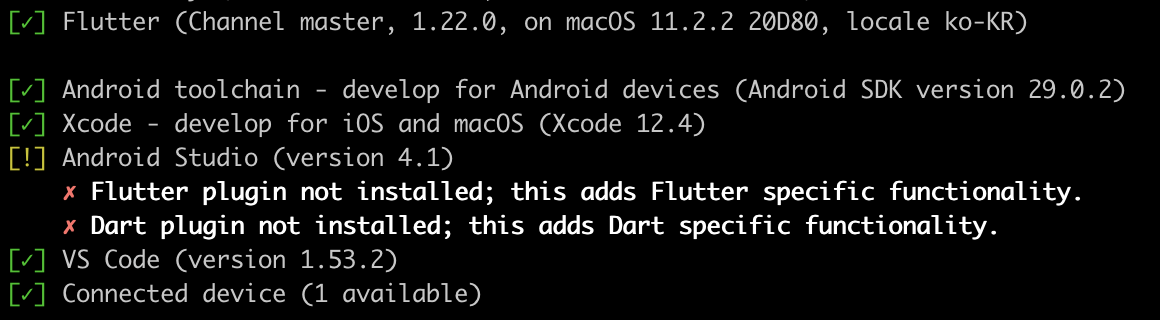
에러 메세지가 확~ 사라졌습니다. 이제 마지막으로 남은 것은 안드로이드 스튜디오에서 플러그인을 설치하는 일입니다. 에..? 플러그인? 분명히 설치했다고 생각했는데... 무슨 문제일까요? 일단 에러 메세지를 무시하고 코드를 안드로이드 에뮬레이터에서 실행해 보겠습니다. 희안하게도 문제 없이 실행이 됩니다.
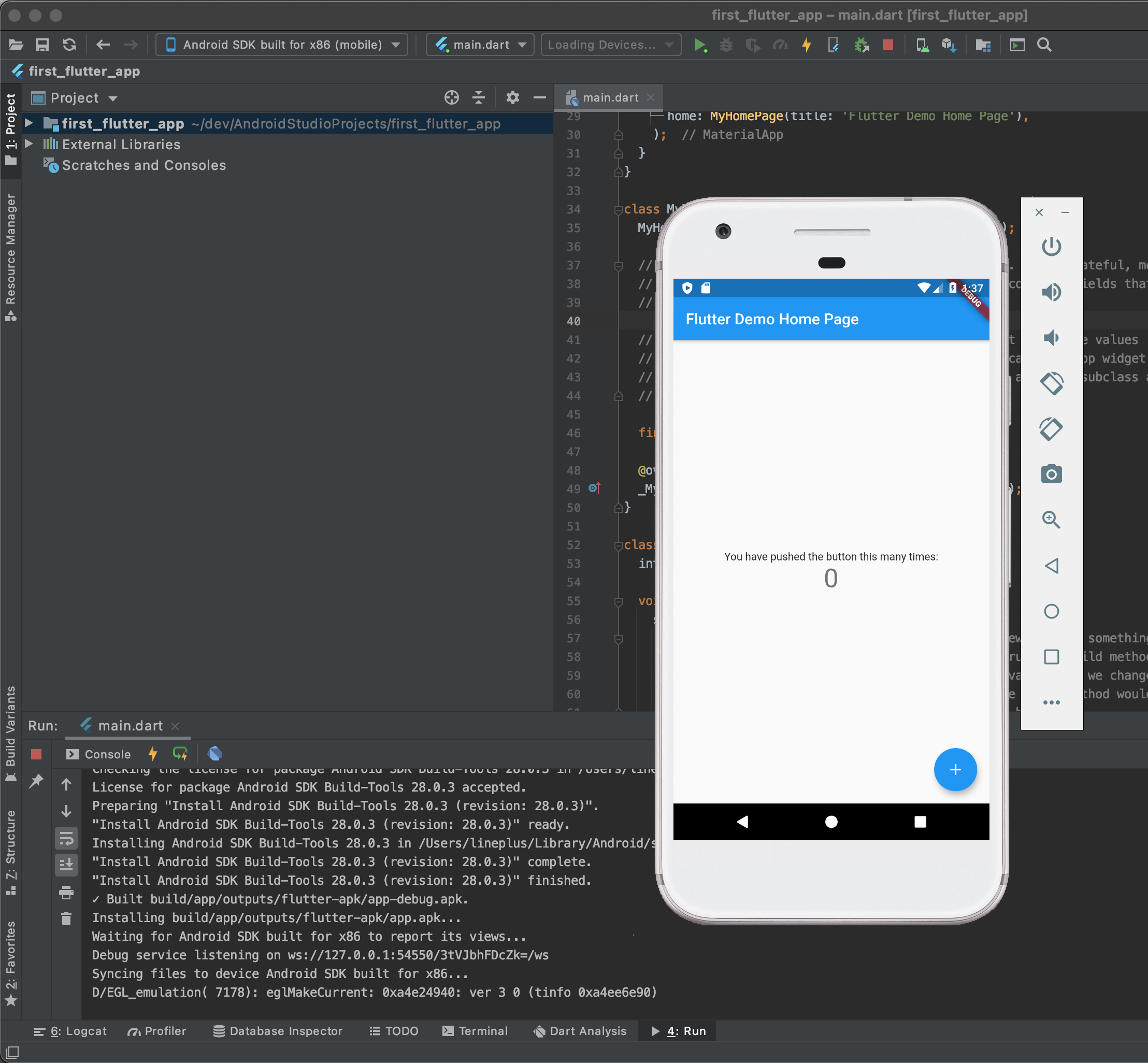
어렵지 않죠? 네, 저는 어렵습니다 ㅎㅎ. 일단 동작이 잘 되는 것을 확인했으니, 본격적으로 뭔가를 만들어 봐야겠습니다!