컨테이너가 잘 뜰까요? 그렇지 않습니다. nginx는 speedtest 이름을 찾을 수 없어서 업스트림 호스트를 찾을 수 없다는 에러를 뿜습니다.
2022/06/18 03:16:21 [emerg] 1#1: host not found in upstream "speedtest:80" in /etc/nginx/conf.d/default.conf:7
2022/06/18 03:20:00 [emerg] 1#1: host not found in upstream "speedtest:80" in /etc/nginx/conf.d/default.conf:7
2022/06/18 03:34:04 [emerg] 1#1: host not found in upstream "speedtest:80" in /etc/nginx/conf.d/default.conf:7
docker-compose 파일을 수정하여 별도의 bridge 네트워크를 만들어 두 컨테이너가 서로 통신하도록 해보겠습니다.
docker bridge 네트워크 구성하기
docker는 다양한 네트워크를 구성을 제공합니다. 그 중에서 우리의 요건에 맞는 것은 bridge 네트워크입니다. 말그대로 다리처럼 컨테이너들이 소통할 수 있는 구조입니다.
파이썬을 사용하여 XML을 다룰때 BeautifulSoup을 많이 사용합니다. 새로 환경을 구성하여 BeautifulSoup을 이용하는데 이전에 보지 못했던 에러가 발생했습니다.
강의 예제 코드 돌리다만난 에러라니...
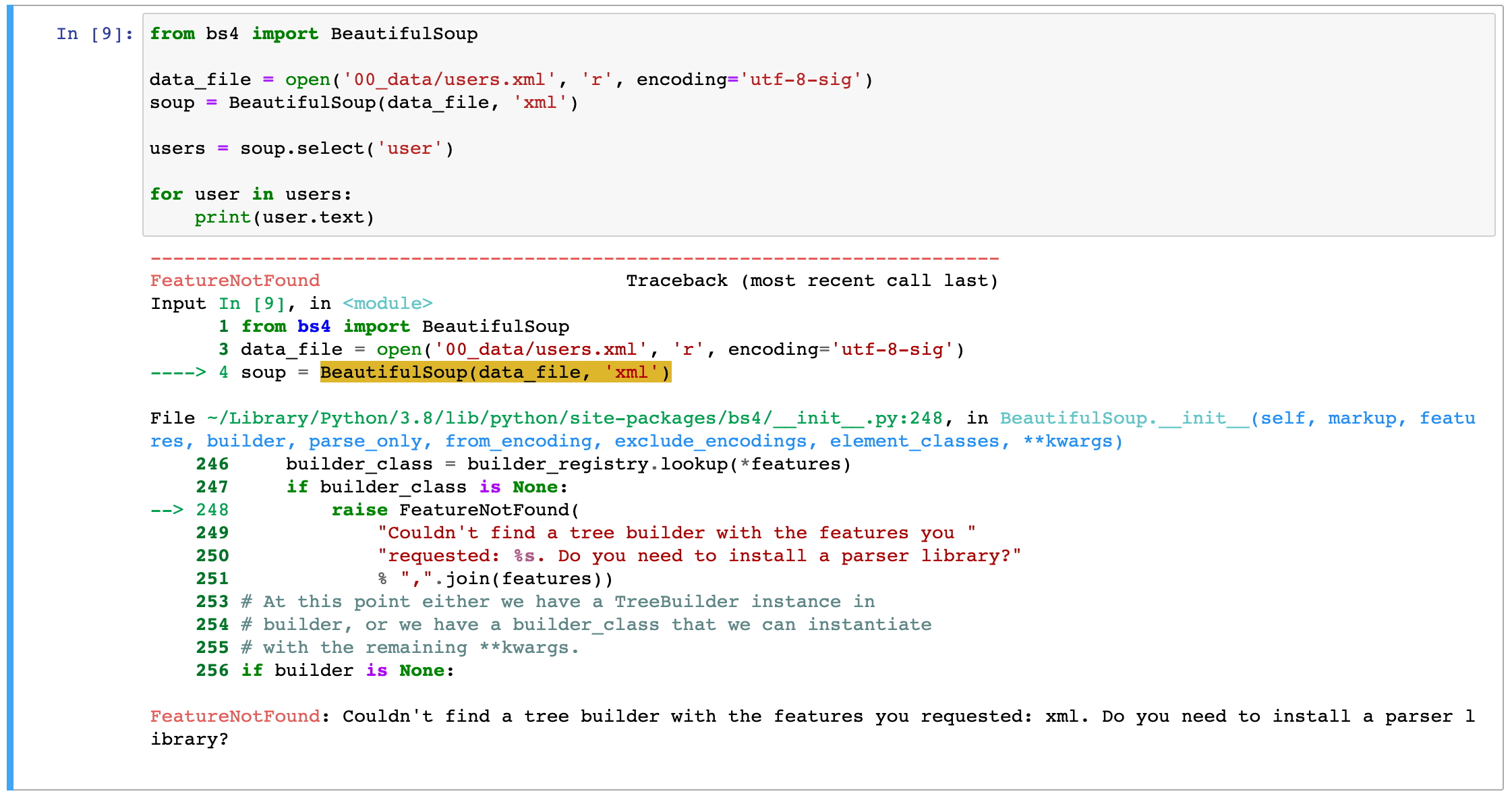
핵심 에러 메세지는 다음과 같습니다. BeautifulSoup 사용시 지정한 Feature가 없다는 내용입니다.
FeatureNotFound: Couldn't find a tree builder with the features you requested: xml. Do you need to install a parser library?
lxml 패키지 설치하기
`xml`이 문제라고 하는데 정확히 어떤 라이브러리를 설치해야 하는지 알려주지는 않는군요. 구글을 통해 검색을 해보니 `lxml` 라이브러리의 설치가 필요한 것 같습니다. Jupyter 노트북을 사용중이라 아래와 같이 설치를 진행해 봤습니다.
!pip 로 주피터 노트북에서 직접 패키지를 설치해 봅니다
설치가 되었으니 이제 잘 되겠지...했으나... 계속 패키지가 없다고 에러가 나옵니다. 난감하네요.
하아... 계속 에러가...
그래서 조금 더 검색을 해보니 주피터 노트북을 재기동 하라는 이야기가 있습니다. 구동중인 주피터를 중지하고 다시 실행했습니다.
Shutdown this notebook server (y/[n])? y
[C 11:01:20.436 NotebookApp] Shutdown confirmed
[I 11:01:20.439 NotebookApp] Shutting down 3 kernels
[I 11:01:20.443 NotebookApp] Kernel shutdown: 7a48be4a-c426-427b-b974-e8e26fccc994
[I 11:01:20.443 NotebookApp] Kernel shutdown: 45325d5b-9d8f-4f43-956f-d2b030475625
[I 11:01:20.443 NotebookApp] Kernel shutdown: d1b14c79-3741-4a14-9d0c-a5fe03a65532
[I 11:01:20.567 NotebookApp] Starting buffering for 45325d5b-9d8f-4f43-956f-d2b030475625:2d7ed833d3fe445c8b3ad49096ce9deb
[I 11:01:20.571 NotebookApp] Kernel shutdown: 45325d5b-9d8f-4f43-956f-d2b030475625
...
...
[I 11:01:20.967 NotebookApp] Shutting down 0 terminals
%
% jupyter notebook
[I 11:01:28.154 NotebookApp] Serving notebooks from local directory: /Users/nopd/dev
[I 11:01:28.154 NotebookApp] Jupyter Notebook 6.4.8 is running at:
[I 11:01:28.154 NotebookApp] http://localhost:8888/?token=731a38a75b038a956951174a7aa6da6d75acd13fe855ebd6
[I 11:01:28.154 NotebookApp] or http://127.0.0.1:8888/?token=731a38a75b038a956951174a7aa6da6d75acd13fe855ebd6
[I 11:01:28.154 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 11:01:28.157 NotebookApp]
To access the notebook, open this file in a browser:
file:///Users/nopd/Library/Jupyter/runtime/nbserver-45577-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=731a38a75b038a956951174a7aa6da6d75acd13fe855ebd6
or http://127.0.0.1:8888/?token=731a38a75b038a956951174a7aa6da6d75acd13fe855ebd6
다시 파일을 열어 코드를 실행해보니 이제 잘 됩니다.
주피터 재기동후 성공!
요약
0. 에러를 만난다 1. 에러를 잘 보고 필요한 패키지를 찾는다 : lxml 2. 주피터 노트북을 재기동한다 3. 계속 파이썬 코드를 잘 짠다
Grafana 8.x 이상 버전에서는 웹 소켓을 이용하여 업데이트 되는 데이터를 패치해 옵니다. 이전에는 별도의 HTTP Request를 이용했지만, 이제는 웹 소켓을 이용해 매번 연결을 보내는 오버헤드를 줄이려는 의도라고 생각합니다. Grafana 에서는 이 기능을 Grafana Live라 부릅니다.
Grafana 인스턴스가 직접 엔드포인트를 제공하면 웹 소켓 이용에 특별한 문제가 없으나 여러가지 이유로 앞단에 NGINX 등을 통한 리버스 프락시를 구현해 두었다면 웹 소켓 연결이 제대로 맺어지지 않는 문제가 있습니다.
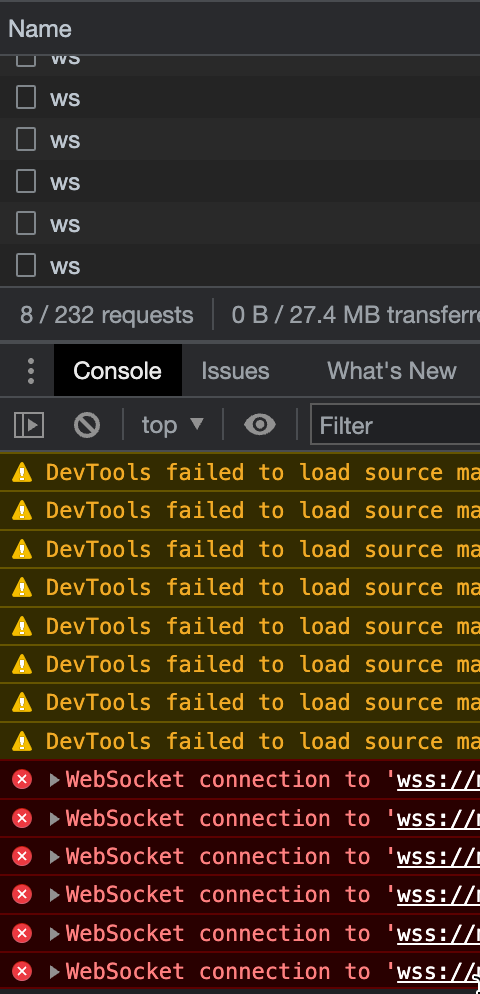
물론 Grafana 의 동작 자체는 문제가 없고 브라우저 개발자 도구/콘솔상에 보기 싫은 빨간색 에러가 잔뜩 찍히는 불편함이 있습니다.
보기 싫은 에러들... ㅜㅜ
방법#1. Grafana Live 기능을 꺼버리자!
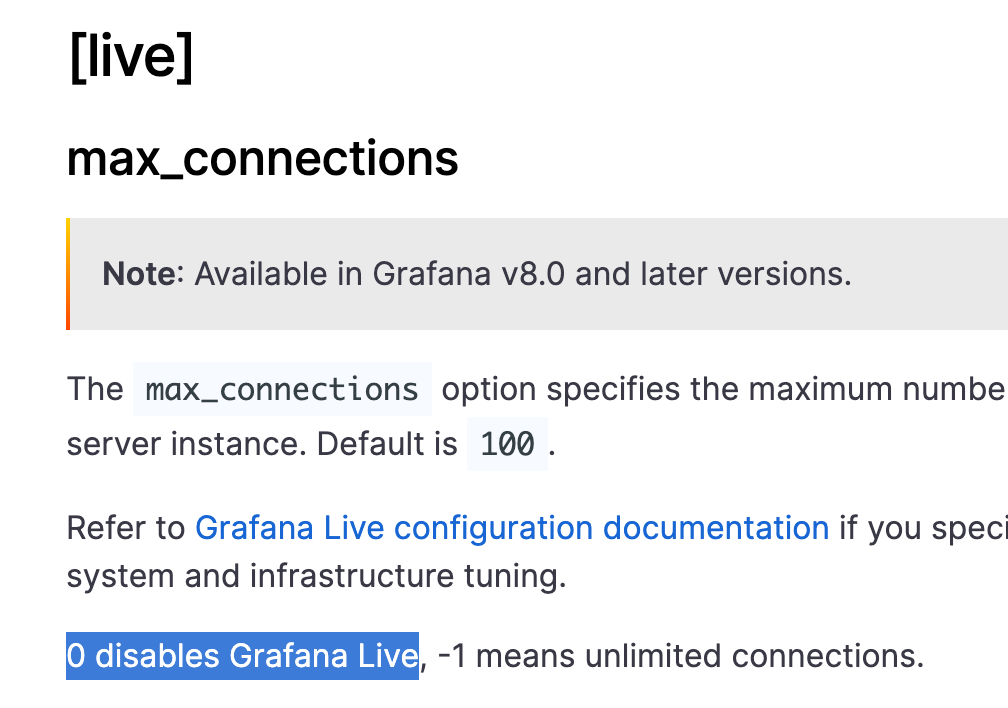
가장 쉬운 방법은 Grafana Live 기능을 꺼버리는 방법입니다. 다만 이 방법은 Grafana Live 문서에서 이야기 하고 있는 기술의 장점을 버리는 선택이 됩니다. 그렇지만 굳이 필요 없다면 기능을 꺼버리는 것이 여러모로 더 나은 선택일 수도 있습니다.
Grafana 설정 파일인 grafana.ini 혹은 custom.ini 에 [live] 섹션을 찾아 max_connections 값을 0으로 설정하면 기능을 끌 수 있습니다.
방법#2. 리버스 프락시에 웹 소켓 설정을 추가하자!
조금 더 적극적인 사용자이고 새로운 기술들을 활용해 보고 싶다면? 구성해 둔 리버스 프락시의 설정을 업데이트하여 웹 소켓을 잘 소화하도록 수정할 수 있습니다. 여기에서는 가장 널리 사용되는 nginx를 리버스 프락시로 사용한 경우입니다.
웹 소켓은 hop-by-hop, 즉 클라이언트와 nginx, 그리고 nginx와 Grafana 사이의 연결을 별도로 취급합니다. 클라이언트가 Grafana와 웹 소켓을 통한 데이터 교환을 하기 위해서는 nginx가 웹 소켓과 관련하여 일종의 터널링을 해주어야 합니다. 마치 nginx가 없는 것처럼 클라이언트와 Grafana 사이를 연결해 주어야 하는 것입니다.
사용자 환경에 따라 nginx 설정 파일을 쪼개서 쓸 수도 있기 때문에 공식 문서에서 가이드 하고 있는 예제 설정을 가져왔습니다.
웹 소켓은 Upgrade 헤더를 이용하여 웹 소켓 사용이 가능한지를 체크하고 문제가 없는 경우에만 커넥션을 맺고 데이터를 흘리는 구조입니다.
설정의 내용은 클라이언트와 nginx 간에 Upgrade 헤더 값에 따라 변수($connection_upgrade) 값을 지정하고 이 값을 Grafana로 요청을 보낼때 사용하는 방식입니다.
마지막의 location 블록을 보면 클라이언트가 보낸 Upgrade 헤더 값($http_upgrade)을 Upgrade 요청 헤더에 지정하고 map 블록으로 지정한 $connection_upgrade 변수 값을 Connection 헤더에 담아 Grafana로 보내는 것을 확인할 수 있습니다.
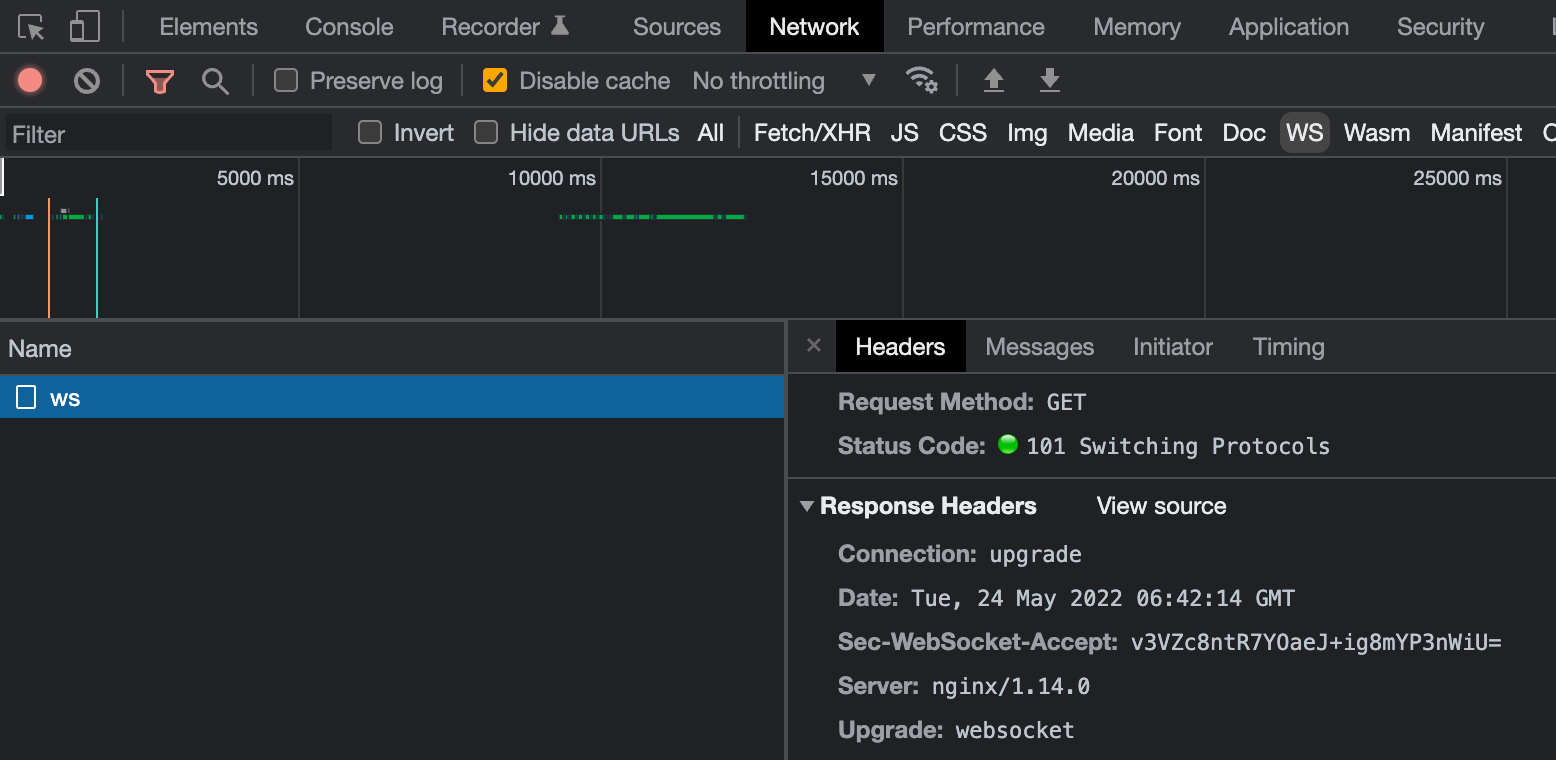
이렇게 설정하고 nginx config을 리로드 하면 에러가 깔끔하게 사라집니다!
깔끔합니다! 101 응답도 잘 내려왔네요!
nginx 기준으로 위와 같은 형태로 구성하는 것은 1.13.x 이후 버전부터 가능합니다. 혹시나 예상대로 잘 동작하지 않으면 nginx의 버전을 살펴보기 바랍니다!
꾸준히 판매되고 있는 저의 번역서 NGINX 쿡북! 아직 구매하지 않았다면 아래 링크로 고고씽~ 구매 달려주시기 바랍니다!
데이터베이스 마이그레이션은 참 번거로운 작업입니다. 상황에 따라서는 메인터넌스를 걸고 서비스를 잠시 중단해야 할 수도 있고 그걸 원하지 않는다면 dual-write 등의 수단을 통해 데이터베이스를 싱크업 하는 과정을 수행해야만 합니다.
마이그레이션이 이번 글의 주제는 아닙니다. 다만 마이그레이션이 필요하지만 메인터넌스 윈도우를 만들고 싶지 않아 데이터베이스를 매뉴얼하게 옮기는 것을 고민하다 문득 <데이터베이스의 모든 테이블 레코드 갯수를 한번에 뽑고 싶다>는 자체 요구사항이 생겨 확인한 내용을 정리해 봅니다.
데이터베이스의 모든 레코드 갯수 쿼리
데이터베이스에 있는 모든 테이블의 레코드 갯수를 카운트 하는 것은 아래의 쿼리를 통해 수행할 수 있습니다.
SELECT SUM(TABLE_ROWS)
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = '##데이터베이스이름##';
모든 테이블 단위로 레코드 갯수 그룹화하는 쿼리
데이터베이스 내에 테이블이 많다면 각 테이블별로 레코드 갯수를 카운트 하고 싶을지도 모릅니다. INFORMATION_SCHEMA.TABLES 가 갖고 있는 몇 가지 컬럼을 활용해서 Group By 하면 쉽게 쿼리할 수 있습니다.
SELECT TABLE_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = '##데이터베이스이름##';
앞선 두 포스팅을 잘 따라오셨다면 우리는 CloudWatch Logs의 기본적인 설정을 만들었고 AWS ElasticSearch Cluster까지 만드셨을 겁니다. 이제 만들어진 ES Cluster로 로그를 적재하기 위한 Subscription filter 구성 작업을 해보도록 하겠습니다. CloudWatch Logs의 관리 화면으로 이동하여 설정을 시작하겠습니다.
Log Group에 대한 Elasticsearch subscription filter 설정하기
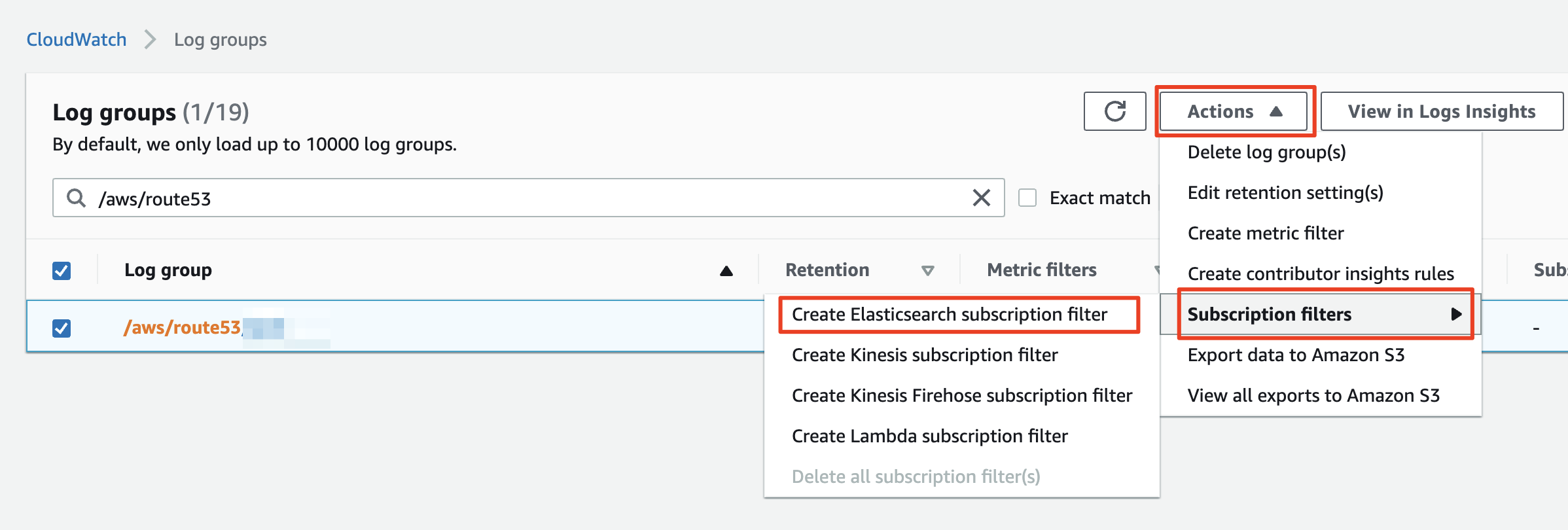
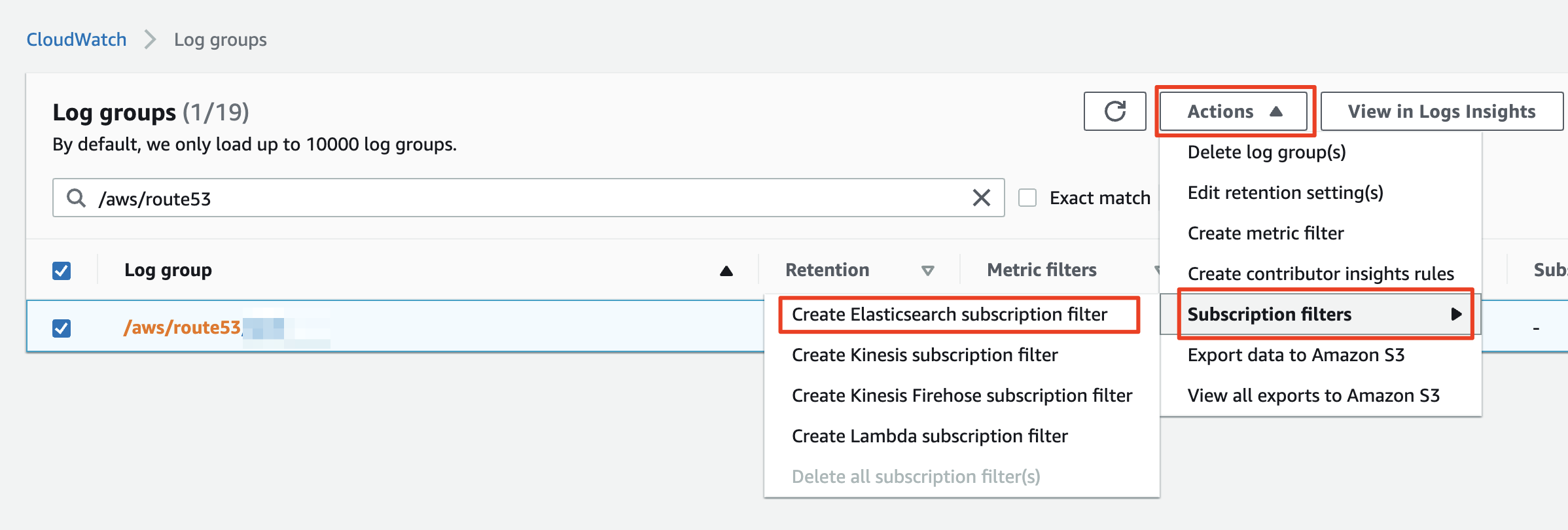
CloudWatch Logs 관리 화면에 진입하면 설정되어 있는 여러 Log Group 목록이 나옵니다. Log Group이 많은 경우 빠른 식별을 위해 제품 명을 Log group 이름에 넣으라고 말씀드렸던 것을 기억하시겠지요? 가이드를 잘 따라오셨다면 검색창에 키워드를 입력하여 쉽게 Log group을 찾을 수 있습니다.
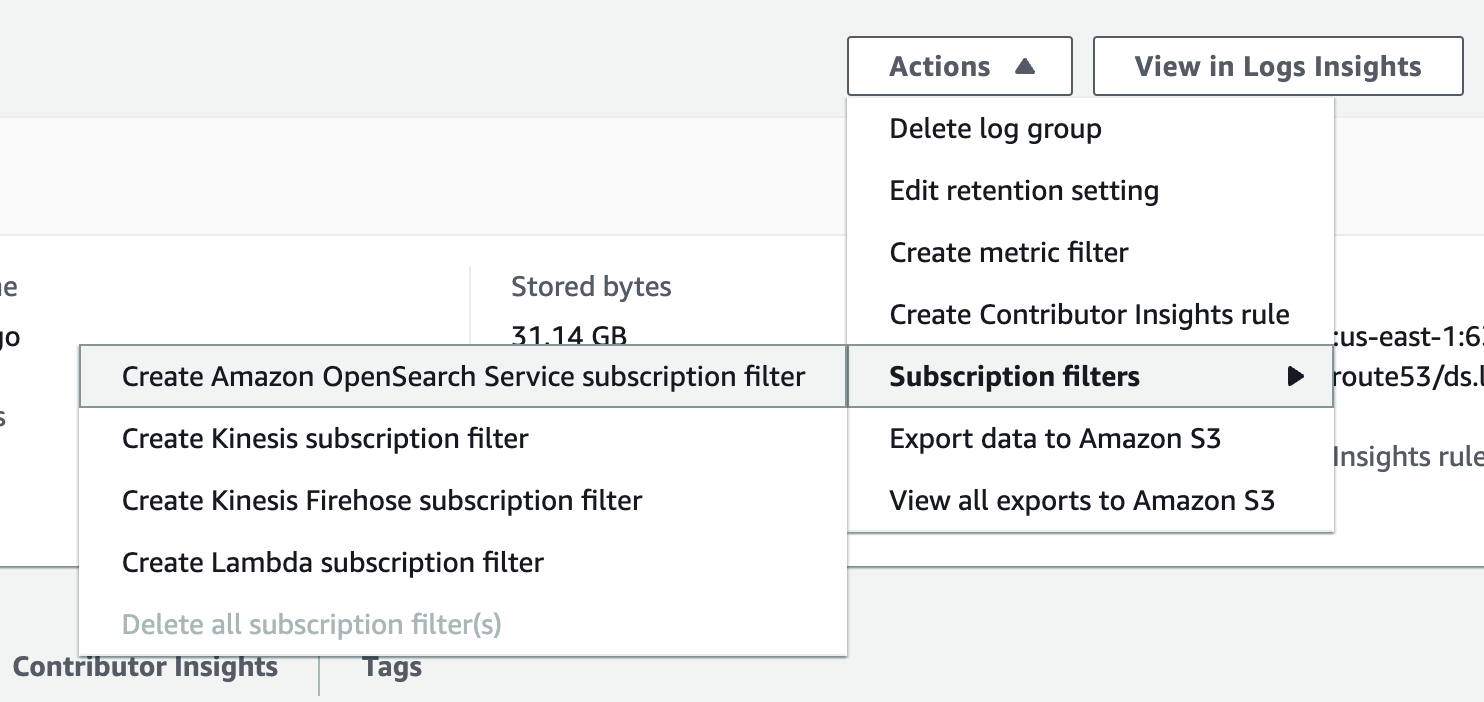
체크 박스로 로그 그룹을 선택하고 상단 `Actions` 드롭다운 메뉴를 누르겠습니다. 메뉴중 `Subscription filters`를 선택하면 4가지 필터 옵션을 선택하는 팝업이 이어집니다. 우리는 첫번째 항목으로 위치한 `Create Elasticsearch subscription filter`를 선택하겠습니다.
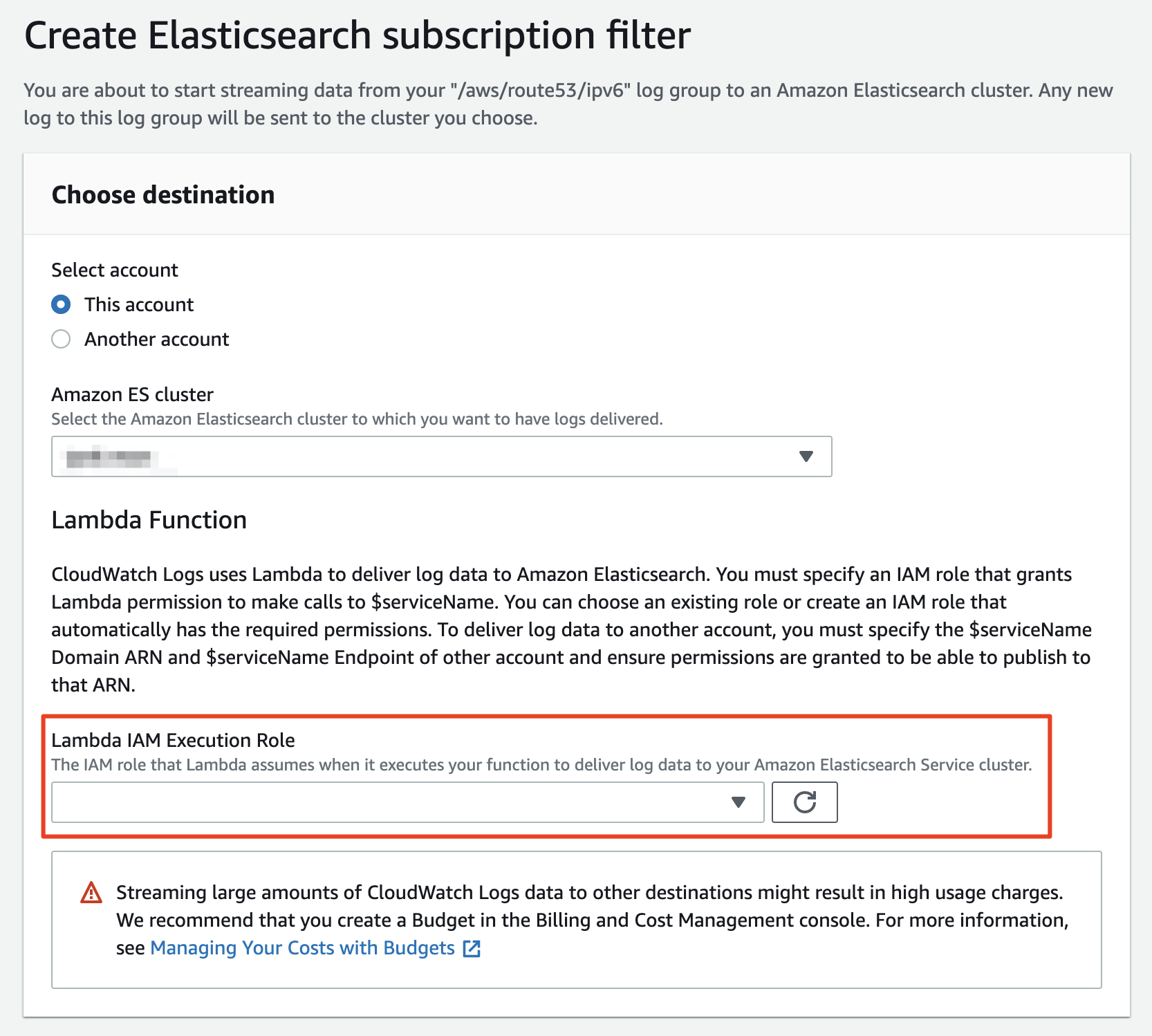
필터 설정 화면은 크게 세 부분으로 나뉘어져 있습니다. 가장 첫번째 섹션은 `Choose destination`입니다. 이곳에서는 로그를 보낼 목적지를 선택하게 되는데요, 우리가 만든 AWS Elasticsearch Cluster의 도메인 이름을 이곳에 지정하게 됩니다.
AWS상에 여러개의 어카운트를 생성하여 사용하고 있다면 `Another account`를 선택하여 다른 어카운트의 ES Cluster로 로그를 전송하는 것도 가능합니다만 이 포스팅의 범위를 넘어서는 내용이니 설명은 따로 하지 않겠습니다. 우리는 기본 값인 `This account`를 선택한 상태에서 설정 작업을 진행하도록 하겠습니다.
간혹 "만들어둔 ES Cluster가 목록에 보이지 않아요!" 라는 분들이 계십니다. ES Cluster는 결국은 EC2를 생성하고 Elasticsearch를 설치, 구동하는 것이기 때문에 생성되는데 생각보다 시간이 좀 걸립니다. 경험상 오래 걸릴때는 10분 정도까지 기다리기도 했으니 혹시나 클러스터 목록에 생성한 ES Cluster가 나오지 않는다면 조금 후에 다시 시도해 보시기 바랍니다. 리프레시 버튼이 없으니 뒤로 갔다가 다시 와야 한다는 점도 기억해 두면 좋겠네요.
첫번째 섹션 `Choose destination`에서 ES Cluster를 선택하면 화면이 늘어나면서 Lambda IAM Execution Role을 선택하라는 안내를 만나게 됩니다. 지금까지 여기저기 옮겨 다니면서 설정을 해왔는데 IAM 으로 다시 또 돌아가야 한다니... 이쯤에서 한숨을 한번 내쉬는 것이 정상입니다 ㅎㅎ 다행히도 우측에 Refresh 버튼이 있기 때문에 별도 창으로 IAM 관리 화면을 열고 Route53로그를 ElasticSearch가 잘 받을 수 있도록 Role을 만들어 보도록 하겠습니다.
그런데 갑자기 왠 Lambda일까요? Lambda가 필요한 이유는 간단합니다. Route53의 로그는 CloudWatch Logs를 통해 수집되면 gzip으로 압축된 상태로 저장됩니다. CloudWatch는 ES Cluster로 이 압축파일을 손대지 않고 그대~~로 전달합니다.. 따라서 이를 Unzip하고 ES에 주입하는 단계가 필요하고 이를 위해서 Lambda를 사용합니다. Lambda 코딩에 자신이 없다구요? 다행히도 우리가 Lambda코드를 만들 필요 없이 적당한 권한만 할당되면 미리 준비된 코드가 구동되는 방식입니다.
IAM에서 Lambda용 Role 설정하기
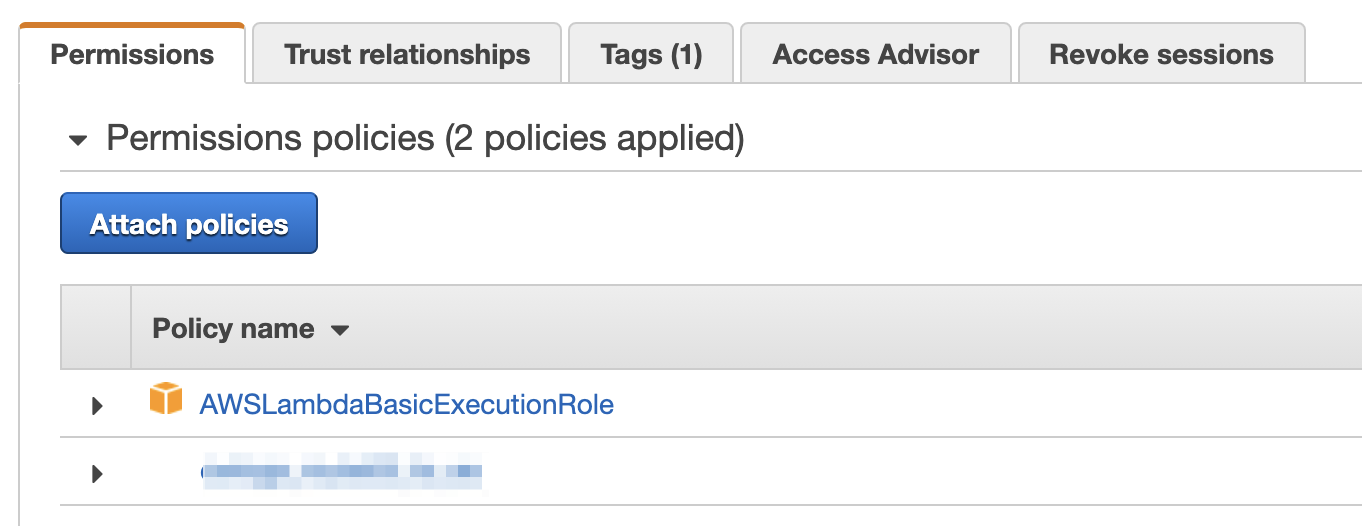
IAM 관리 화면을 별도 창으로 열어보겠습니다. 우리는 IAM의 Roles 메뉴에 진입하여 새로운 Role을 작성하도록 하겠습니다. 아래의 이미지에 나온 것처럼 Permission Policy에 우선 `AWSLambdaBasicExecutionRole`을 붙여 주겠습니다.
(Update 2022.04.22)
AWS Console이 업데이트 되면서 IAM 도 화면이 많이 변경되었습니다. 당황하지 마시고 하나씩~ 보시면서 설정하시면 오히려 더 편리하기도 합니다!
`AWSLambdaBasicExecutionRole`이라는 Managed Policy가 추가 되었다면 `Add inline policy`버튼을 눌러 아래의 JSON을 입력합니다. JSON의 내용중 Resource의 Account ID, Region ID, ES Cluster Name등은 각자의 어카운트 환경과 설정에 맞게 수정해서 넣어야 합니다.
퍼미션 설정이 되었다면 이 권한을 갖게될 계정이 신뢰할 수 있는 서비스를 지정하겠습니다. 생성된 Role을 활용하는 주체는 CloudWatch Logs가 됩니다. CloudWatch Log는 Lambda를 실행해야 하기 때문에 Trusted Relationships에는 lambda.amazonaws.com 서비스를 추가해야 합니다. JSON 기준으로 Trust relationship을 보면 아래와 같습니다. 공통 영역이니 그대로 복사해서 붙여 넣어도 무방합니다.
여기까지 완료되었다면 IAM Role의 설정이 완료된 것입니다. 다시 CloudWatch Logs에서 subscription filter를 선택하던 화면으로 돌아가서 Lambda IAM Execution Role 지정 영역의 Refresh 를 눌러 방금 만든 Role이 나오는지 확인합니다. 저는 기억하기 좋게 cwlogs_route53_to_es 라고 Role 이름을 지었습니다. 생성한 Role을 선택후 다음 섹션으로 넘어가겠습니다.
(Update 2022.04.22)
Lambda IAM 생성/지정하는 부분이 보이지 않는 경우 아직 OpenSearch 클러스터 생성이 완료되지 않은 것입니다. 조금 기다렸다가 다시 Subscription Filter 를 생성하시기 바랍니다.!
아래와 같은 에러가 발생하면 커피 한잔, 담배 한대 피우고 오시기 바랍니다!!!
로그 포맷 설정
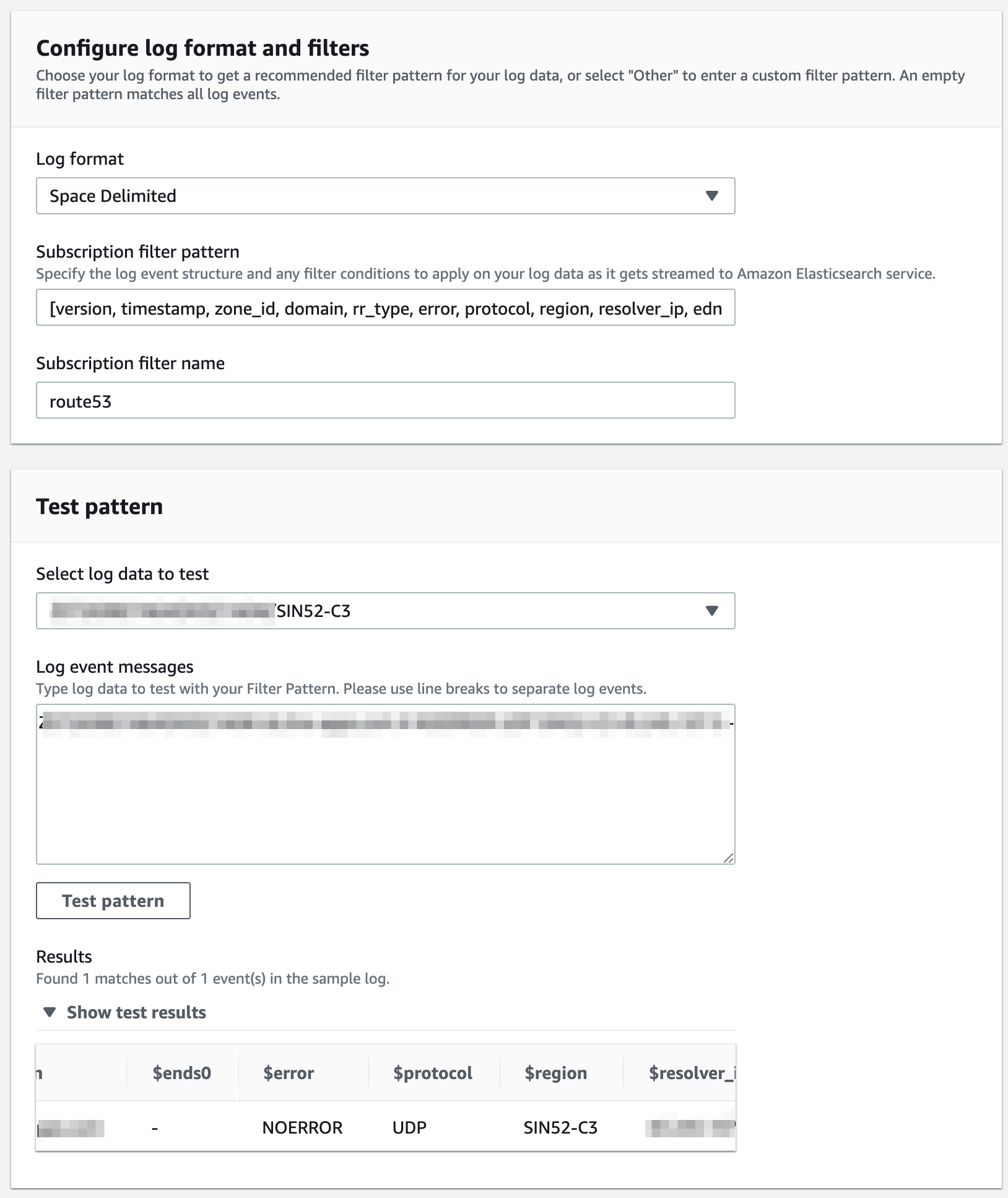
Subscription filters 설정의 두번째 섹션인 `Configure log format and filters`에서는 로그 포맷을 정의하게 됩니다. 정의된 로그 포맷으로 규격을 맞추어 CloudWatch Logs에서 Lambda를 거쳐 ES로 로그가 전달되는 식입니다. 포맷을 별도로 정의하지 않으면 ES에서는 `@message` 컬럼으로만 로그 데이터가 저장됩니다. 따라서 저장된 로그를 조회하거나 다루기 쉽게 하려면 로그 포맷을 지정하는 것이 중요합니다.
안타깝게도 사전에 정의된 Log format 목록에는 Route53이 CloudWatch Logs를 통해 전달하는 포맷 정보가 기본 항목으로 들어 있지 않습니다. 따라서 Log format으로 `Space Delimited`를 선택하고 2021년 8월 기준 로그에 대해서 만든 아래의 내용을 필터 패턴에 넣어주면 ElasticSearch Cluster에서 사용하기 편한 컬럼을 만들고 저장할 수 있게 됩니다.
마지막 섹션인 `Test pattern`에서는 이미 수집되기 시작한 CloudWatch Logs의 샘플 로그를 이용하여 입력한 filter pattern이 데이터를 잘 구분해 내는지 확인해 볼 수 있습니다. 앞선 포스팅에서 확인했던 것처럼 이미 로그가 쌓이고 있을 것이기 때문에 쌓인 로그 중 하나를 선택하여 입력한 필터가 데이터를 잘 구분해 주는지 확인해 보겠습니다.
데이터가 잘 쌓이고 있고 필터가 적당히 구성되었다면 위 그림에서 볼 수 있는 것처럼 로그를 잘 구분하고 있는 것을 확인할 수 있습니다. 이제 모든 구성이 끝났으니 화면 맨 아래의 `Start streaming`을 눌러 데이터 전송을 시작하겠습니다. 문제가 없다면 성공 메세지와 함께 Subscription filters가 생성된 것을 확인할 수 있습니다.
지난 글에서는 Route53 로그 추출을 위한 사전 작업으로 Route53의 대상 Hosted Zone에 Query Logging을 설정하고 CloudWatch Logs로 로그를 전송하도록 구성을 했습니다. 로그가 정상적으로 CloudWatch Logs로 수집되기 시작했기 때문에, 이번 글에서는 `Subscription filters`를 생성하여 <로그를 구독할 서비스를 설정>하고 CloudWatch Logs의 로그를 해당 서비스가 구독하도록 하겠습니다.
다만 이 작업을 진행하기 전에 Amazon ElasticSearch를 향한 `Subscription filters` 생성시 입력해야 하는 ElasticSearch Cluster 도메인을 먼저 만들고, 해당 도메인을 filter에 지정하는 작업을 해보도록 하겠습니다. 참고로 CloudWatch Logs에서 생성할 수 있는 filter는 4가지 정도가 있습니다만 AWS ElasticSearch로 전송하는 것이 가장 간단합니다.
(Update 2022.04.21)
AWS의 제품 라인업에서 ElasticSearch가 빠지고 Amazon OpenSearch로 대치되었습니다. ES의 오픈소스 버전이라고 생각하면 되기 때문에 기본적으로 큰 차이는 없습니다!
Amazon Elasticsearch Cluster 생성하기
`Elasticsearch subscription filter`를 설정하기 위해서 AWS Web Console 에서 `Amazon Elasticsearch`를 선택하고 관리 화면으로 이동하도록 하겠습니다. 제가 사용하는 Account에는 생성된 ES Cluster가 없기 때문에 아래 화면과 같습니다만, 미리 생성되어 있거나 사용중인 ES Cluster가 있다면 목록에 해당 클러스터의 이름이 보일것입니다.
어쨌든 우리는 새로운 클러스터를 만들어야 하기 때문에 `Create domain`을 눌러 새로운 ElasticSearch Amazon OpenSearch Cluster를 구성해 보도록 하겠습니다. 새로운 클러스터 생성시 `도메인`을 지정하게 되고, 이후 CloudWatch에서 subscription filter를 설정할 때도 생성한 도메인 이름을 선택하게 됩니다.
간단하게 짧은 시간동안 Route53 DNS의 로그를 수집하여 분석해야 하거나 로그 양이 많지 않은 경우라면 클러스터에 사용되는 리소스 규모를 적당한 크기로 선택하는 것이 좋습니다. ElasticSearch 생성의 첫 단계에서 `Development and testing` 타입으로 클러스터를 생성해도 무방할지 생각해 보시기 바랍니다. 설명에 따르면 이 옵션을 쓰면 AWS Region의 가용성 영역을 하나만 사용하게 되고 HA(High Availability)를 보장받기 힘듭니다. 그럼에도 불구하고 우리는 공부를 하는 중이니 간단하게 클러스터를 구성하도록 하겠습니다.
두번째 화면에서는 할당될 Elasticsearch 클러스터의 도메인(Domain)으로 사용할 키워드를 입력합니다. 앞서 이야기 한 것처럼 여기에서 입력한 키워드를 클러스터 선택시 사용하게 됩니다. 이외에도 자동 튜닝, 인스턴스 타입, 스토리지 크기 등을 정하게 됩니다만 크게 필요가 없다면 옵션을 끄는 것이 비용 관점에서 유리합니다. 물론 성능이 좋은 ES 클러스터를 만들어야 한다면 세세하게 설정을 손봐야 하겠지만 일단 로그를 흘리면서 ES로 던지고, ES와 함께 제공되는 Kibana에서 조회해 보는 것이 목적이니 기본 값으로 시험해 봐도 무방하다.
(Update 2022.04.21)
Amazon OpenSearch 로 제품이 변경되면서 설정 화면이 약간 바뀌었습니다. 아래와 같이 `Deployment type` 선택이 약간 아래로 밀렸고 Name 지정을 먼저 하도록 바뀌었습니다. 순서만 약간 바뀌었을 뿐, 입력하고 선택하는 내용은 대부분 큰 변경이 없습니다.
1. 먼저 Domain Name과 Deployment Type을 선택합니다. 시험중이라면 `Development and testing`을 선택하여 단일 리전에만 배포합니다.
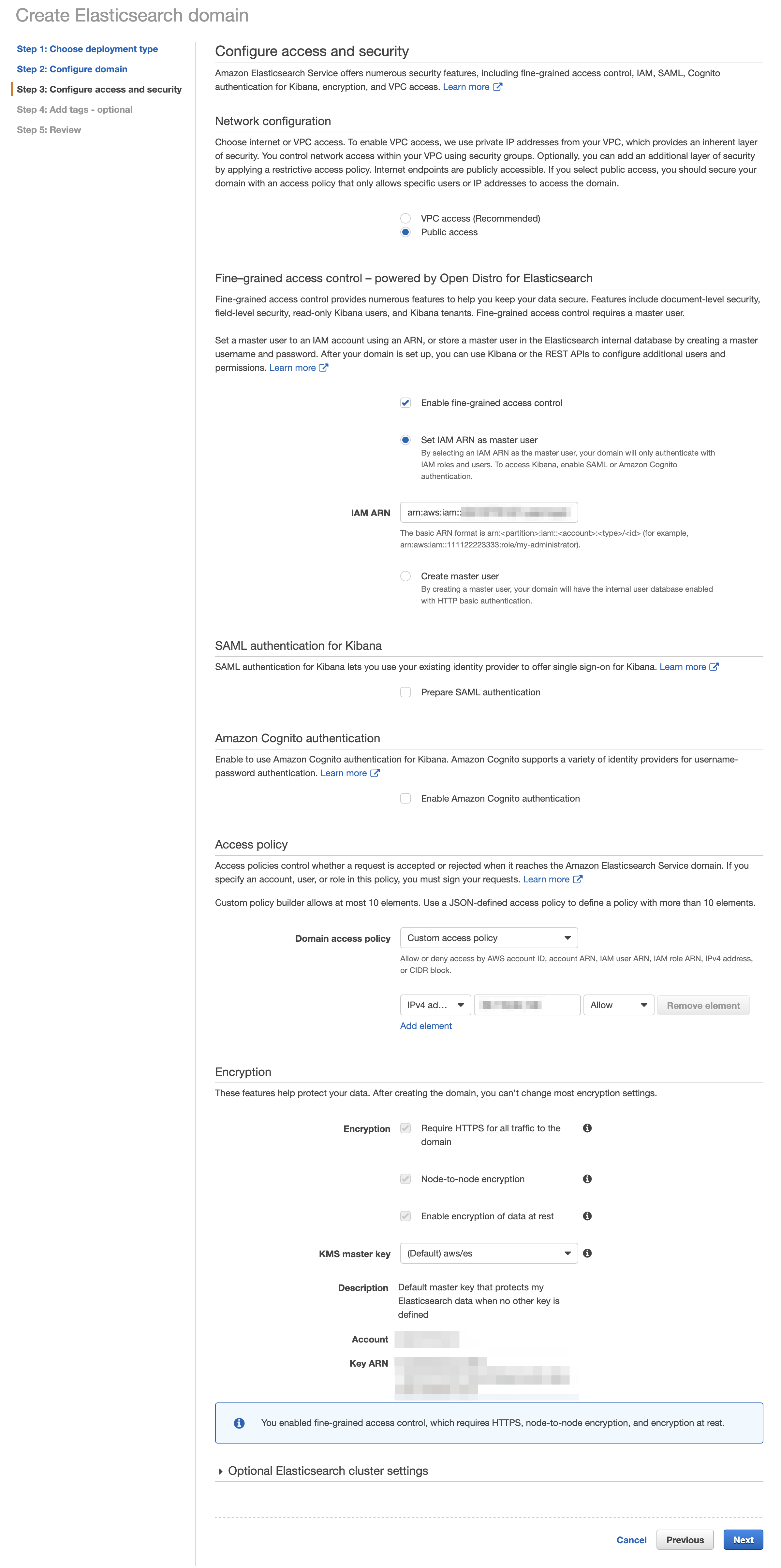
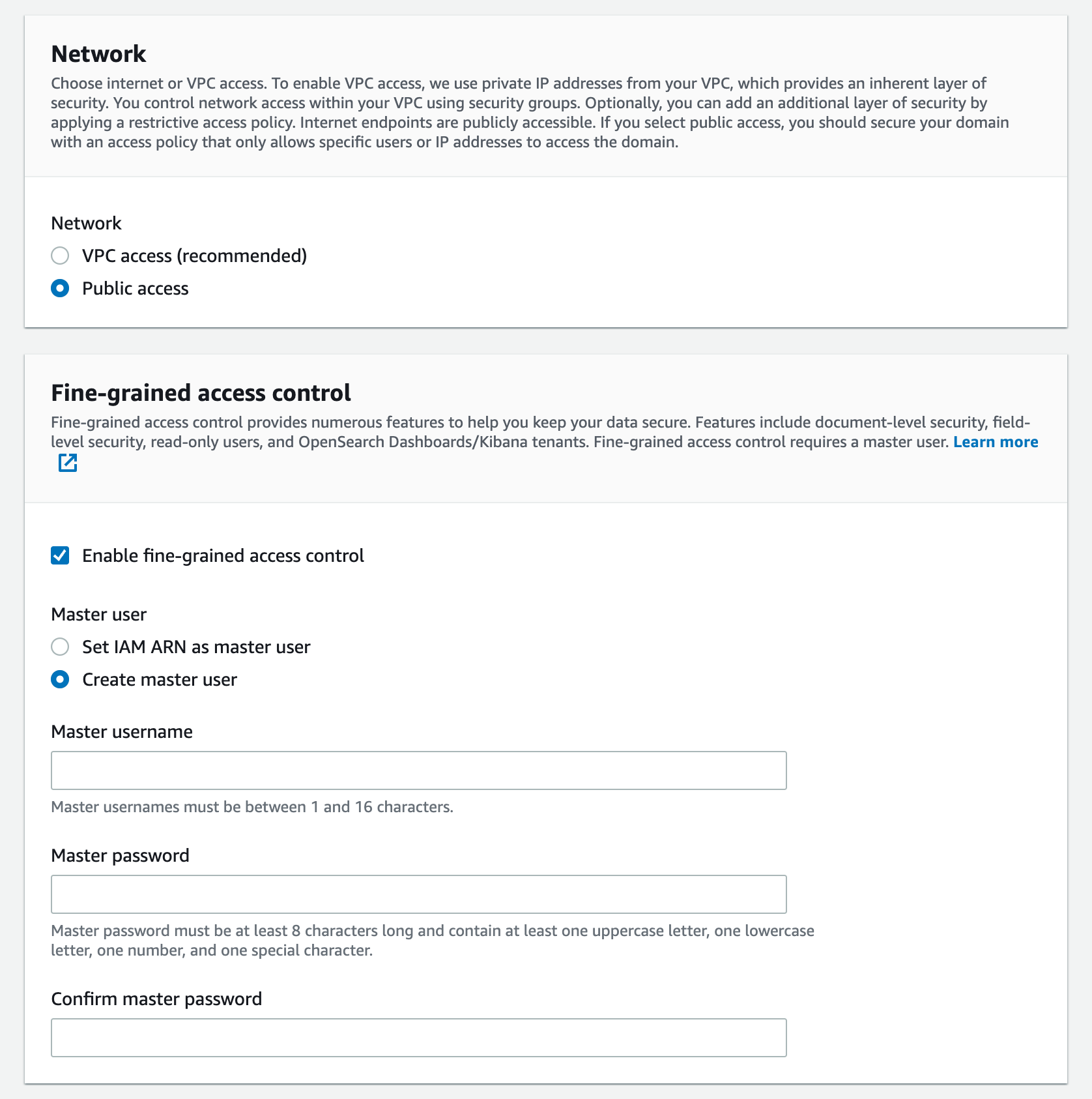
다음으로 ES와 Kibana에 접근할 수 있는 접근 권한을 설정해야 합니다. VPC내에서만 접근 가능하게 하거나 Cognito 등을 연동하여 IAM 기반으로 접근할 수 있도록 하는 것이 좋습니다만 시험을 위해서 Public Access로 구성을 진행하고 <Fine-grained access control> 섹션에서 `Create master user`를 눌러 단순하게 ID, Password로 접근하게 하는 방법을 써도 무방합니다. Production용 시스템을 구성한다면 이렇게 구성하지 않는 것이 Job Security에 유리하겠습니다 :-)
(Update 2022.04.21)
시험적으로 만들어보는 중이니 `Network`는 `Public access`로 `Fine-grained access control`도 `Create master user`를 이용하도록 합시다. 이전 버전과 큰 차이는 없습니다.
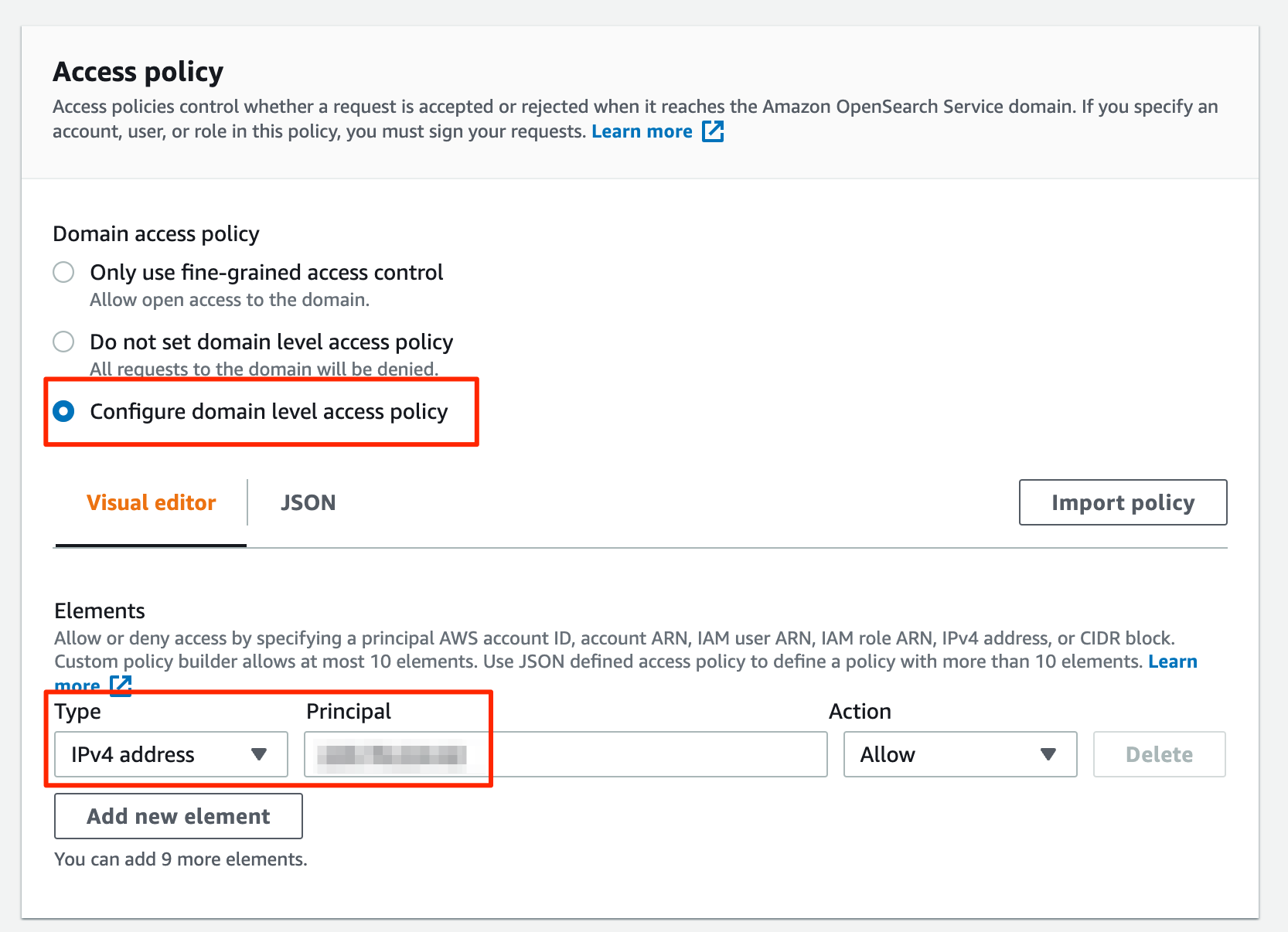
`Access Policy` 역시 단순한 시험을 위해 IP ACL로 설정해 보았습니다.
이후 AWS의 꽃 중 하나인 Tag 설정 단계가 있지만 시험용 설정을 위해서는 굳이 설정하지 않아도 됩니다. 마지막으로 `Review` 단계에서 입력한 값들을 한번 더 검증하고 문제가 없다면 `Confirm` 버튼을 눌러 ElasticSearch Cluster 생성을 마무리 하도록 하겠습니다.
늘 느끼는 것이지만 AWS를 비롯한 Public Cloud에서는 이것 저것 설정하고 준비해야 할 것들이 꽤 많습니다. 이어지는 글들에서는 CloudWatch Logs에서 Subscription filter를 생성하고 IAM에서 필요로 하는 권한을 설정하는 작업을 진행하도록 하겠습니다.
AWS Route53은 Authoritative DNS로도 사용될 수 있고 Dynamic DNS 혹은 GSLB(Global Server Load Balancer)로도 사용될 수 있습니다. 쿼리 수량에 따라 단가가 매겨지고 (=TTL조정으로 어느정도 비용 통제도 할 수 있...) 레코드 수량에 대한 비용 부담이 없기 때문에 요청량이 많지 않은 경우 비용이 꽤 저렴한 편이기도 합니다.
여튼, 이런저런 목적으로 Route53을 사용하게 되면 Route53에 대한 모니터링을 하고 싶어지는게 인지상정입니다. CloudWatch에서 기본적으로 제공되는 Route53의 메트릭들이 있긴 하지만 DNS 쿼리 자체에 대한 성공, 실패와 같은 모니터링은 CloudWatch의 메트릭으로는 모니터링이 불가합니다.
서버의 Access Log를 분석하는 것처럼 Route53의 쿼리 질의 및 결과를 모니터링 하려면 CloudWatch가 제공하는 Logs기능을 이용해야 합니다. Route53에 구성한 Zone으로 들어오는 요청을 CloudWatch Logs로 수집하고 다시 이것을 ElasticSearch 등의 데이터 분석 도구로 전달하는 모니터링 체계를 만들어 보도록 하겠습니다.
Route53 Hosted Zone에 Query Logging 설정하기
Route53에서 관리하는 Zone을 Hosted Zone이라 부릅니다. 개별 레코드를 만들어 Route53에 위임하는 경우도 있고, 혹은 최상위 Zone 자체를 Route53에서 관리(=Authoritative NS)하는 경우도 있습니다. 어느 경우던 기본 단위는 Hosted Zone이고 로그 수집의 최소 단위도 Hosted Zone입니다.
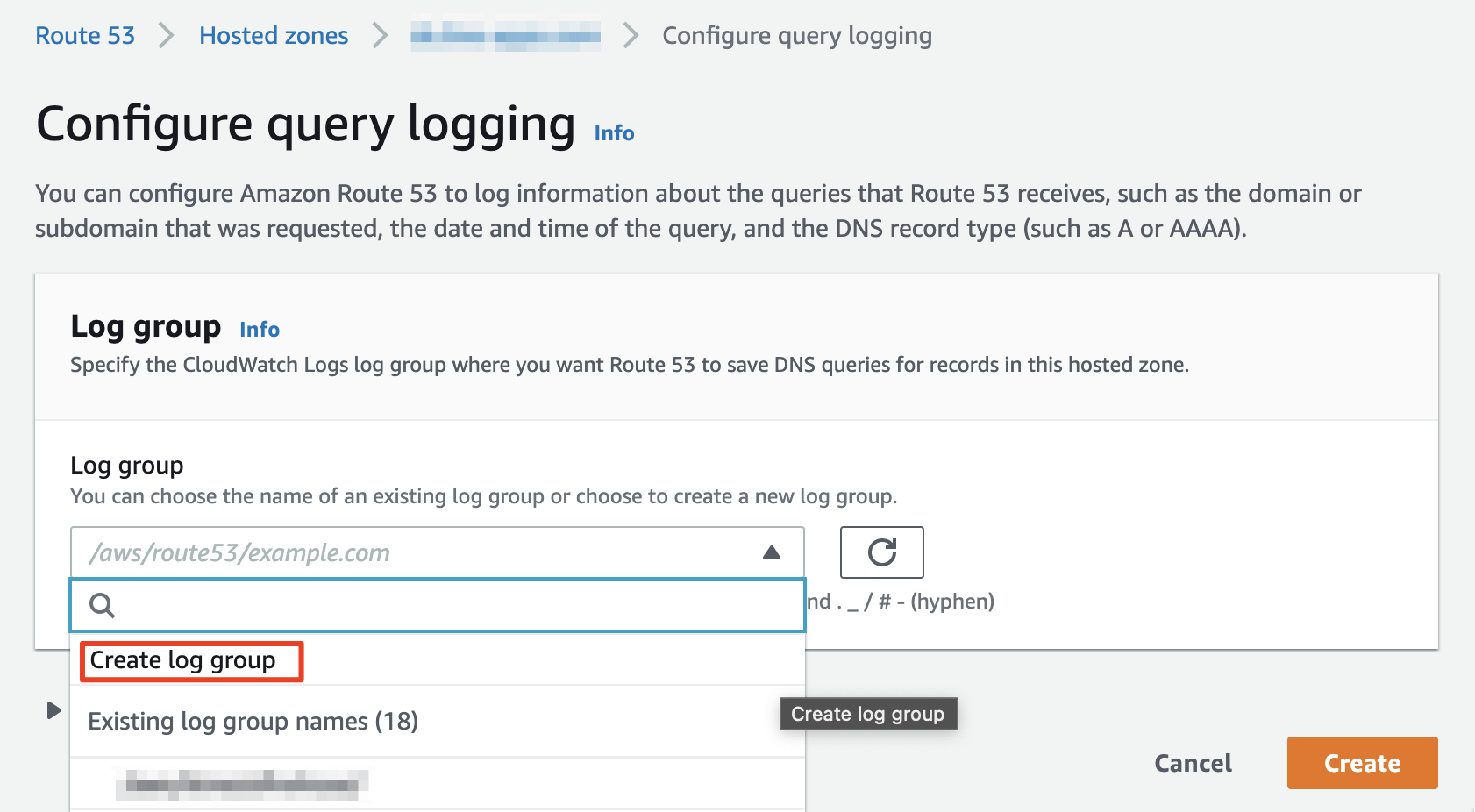
Route53에 구성한 Hosted Zone에 대하여 로깅을 하기 위해서는 AWS CloudWatch Logs를 이용해야 합니다. CloudWatch Logs로 로그를 전달하기 위해서는 Route53에서 로그를 전송하고자 하는 Hosted Zone 관리 화면으로 이동하여 기능을 활성화 해야 합니다. Hosted Zone 관리 화면에 진입하면 우측 상단에 `Configure query logging`이라는 버튼을 확인하실 수 있습니다.
Query logging 기능 활성화는 무척 단순합니다. 새로운 Log Group 을 만들기 위해 `Create log group`을 선택하고 만들고자 하는 Log Group의 이름을 입력하면 됩니다. 이미 만들어 둔 Log Group이 있다면 해당 Log Group을 선택해도 무방합니다. 다만 그 경우 다른 성격의 Log가 섞일 수도 있겠죠?
Log Group의 이름은 식별이 용이하도록 Place Holder에서 가이드 하는 것처럼 `/aws/route53/#zone이름#`을 사용하는 것을 권장드립니다. 물론 `/aws`를 넣는것이 필요한가는 잘 모르겠습니다만... 여튼 그렇습니다. 값을 입력하고 하단의 `Create`버튼을 누르면 Log Group이 생성되고 다시 Hosted Zone 관리 화면으로 이동하게 됩니다.
CloudWatch Logs에서 생성된 Log Group 확인
Route53 관리 화면에서 Log Group 생성을 마쳤으면 CloudWatch 관리 화면으로 이동하여 생성된 Log Group을 확인해 보도록 하겠습니다. CloudWatch 관리 화면의 왼쪽 메뉴중 `Logs` 하위에 있는 Log groups 메뉴를 선택합니다. 생성되어 있는 Log Group 목록이 출력되면 검색창에 /aws/route53 을 입력하거나 Zone 이름을 입력하여 Log Group을 찾을 수 있습니다.
생성된 로그 그룹에 들어가보면 이미 로그가 쌓이고 있는 놀라운 현상을 경험할 수 있습니다. 여느 인터넷 서비스가 그러하듯 DNS의 세계 역시 수많은 크롤러, 봇들이 돌아다니며 취약점을 가진 서버들을 찾거나 정보를 수집하는 경우가 많습니다. 로그가 쌓이고 있다고 해서 당황할 필요는 없겠죠?
여기까지 완료 되었다면 로그를 모으는 과정은 완료되었다고 보셔도 됩니다. 이제 이렇게 모은 로그를 AWS가 제공하는 데이터 관련 도구로 전달하는 작업을 해보겠습니다. CloudWatch Log는 구독 필터(Subscription filters)를 통해 AWS의 다른 제품으로 로그를 전송할 수 있습니다.
그중 가장 단순하게 구성할 수 있는 것이 Elasticsearch 로 전송하는 방법입니다. 물론 Kinesis Data Stream으로 전송하는 `Kinesis subscription filter`도 있고 Kinesis Data Firehose로 전송하는 `Kinesis Firehose subscriptino filter`도 있습니다. 하지만 이쪽으로 전달하여 로그를 분석하는 것인 본 포스팅 시리즈에서는 다루지 않습니다.