InfluxDB 도 데이터베이스이기 때문에 만일의 상황을 대비하여 백업과 복원 방법에 대하여 알아둘 필요가 있습니다. 근래에 클라우드 기반으로 서비스를 제공하고 있다보니 공식 문서에서 설치형 InfluxDB 인 InfluxDB OSS 로 문서를 찾아보아야 합니다. OSS 버전이 2.0 까지 출시되었지만 사용중인 1.8 버전을 기준으로 내용을 정리해 보겠습니다.

데이터 백업과 복원 절차의 InfluxDB 버전 호환성
SaaS 혹은 PaaS 형 서비스인 InfluxDB Cloud 를 제외하면 우리가 선택할 수 있는 옵션은 두가지 입니다. 하나는 InfluxDB OSS 이고 다른 하나는 InfluxDB Enterprise 입니다. 전사에서 InfluxDB 를 도입해서 쓰는 경우가 아니라면 대부분 OSS 버전이겠습니다만, 중요한 것은 이 두가지 종류간에는 백업 데이터의 상호 호환이 된다고 합니다.
다만, 공식 문서에서 버전에 대한 언급이 있는데요, 메이저 버전이 같아야 상호 백업, 복원이 가능하다고 합니다. 현재 OSS 의 2.0 버전과 1.8 버전 간에는 데이터 호환이 되지 않을 수 있다는 이야기입니다. 문제가 없는 예시로 들고 있는 것은 1.7.3 버전과 1.8.2 버전인데요, 이런 경우에는 문제가 없다고 합니다. 다른 메이저 버전간의 백업, 복원은 그런 상황이 오면 확인해 보도록 하겠습니다 ^^;;
백업 파일은 두가지 포맷이 존재한다!?
InfluxDB 를 백업할 때 사용할 수 있는 포맷은 두가지입니다. 하나는 Enterprise 버전과 호환되는 포맷으로 CLI 에서 백업시 -portable 옵션을 사용해야 합니다. -portable 옵션 없이 백업을 하는 경우 이전 세대의 포맷인 Legacy 버전으로 백업됩니다. Enterprise 버전을 당장 사용할 일이 없다고 하더라도 -portable 옵션을 이용하는 것이 좋아보입니다.
백업된 데이터를 복원할 때도 백업 파일의 버전을 지정해 주어야 합니다. 복원시 -portable 옵션을 주게 되면 Enterprise 버전과 호환되는 포맷의 백업파일을 복원한다는 의미가 됩니다. 백업때와는 달리 Legacy 버전의 데이터를 복원할때는 -online 옵션을 지정해 주어야 합니다.

백업#1 - InfluxDB 로컬에서 백업 수행해보기
기본적인 InfluxDB 의 백업, 복원에 대한 특징과 주의사항을 살펴보았으니 실제로 백업을 해보겠습니다. InfluxDB 를 백업하는 방법은 1) 해당 머신에서 직접 백업하는 방법과, 2) 리모트 접근 포인트를 열어서 백업하는 방법의 두가지가 있습니다. 간단한 것이 1번의 방법이니 로컬에서 백업을 먼저 해보도록 하겠습니다.
$ influxd backup -portable -database myreport ./
2020/11/18 16:22:12 backing up metastore to meta.00
2020/11/18 16:22:12 backing up db=myreport
2020/11/18 16:22:12 backing up db=myreport rp=autogen shard=3 to myreport.autogen.00003.00 since 0001-01-01T00:00:00Z
...
...
2020/11/18 16:22:13 backup complete:
2020/11/18 16:22:13 20201118T072212Z.meta
2020/11/18 16:22:13 20201118T072212Z.s3.tar.gz
...
...
2020/11/18 16:22:13 20201118T072212Z.manifest가장 간단한 방식으로 명령을 만들어 보았습니다. 터미널로 InfluxDB 가 구동되는 서버에 접근하여 CLI 로 명령을 내리시면 됩니다. 첫번째 인자로 backup 을 지정하여 백업 작업의 수행을 알려줘야 합니다. 앞서 살펴본 것처럼 새로운 버전의 포맷을 쓰기 위해 -portable 옵션을 넣었고, 특정한 데이터베이스만 백업하기 위하여 -database 로 데이터베이스 이름(제 경우는 myreport)을 지정해 주었습니다. 데이터베이스가 여러개 생성되어 있고 전체 백업을 진행하려면 -database ##DB명## 을 제외하고 명령을 내리시면 됩니다.
마지막 인자는 백업 파일이 저장될 경로입니다. 명령을 실행하는 디렉토리에 백업 파일을 만들기 위하여 ./ 를 넣었습니다만 각자의 상황에 맞게 경로를 지정해 주면 문제 없을겁니다. 이렇게 명령을 내리고 나면 지정된 경로에 아래와 같이 백업 파일이 생성됩니다. 뭔가 복잡하지만 자세히 알아보지는 않겠습니다 ^^
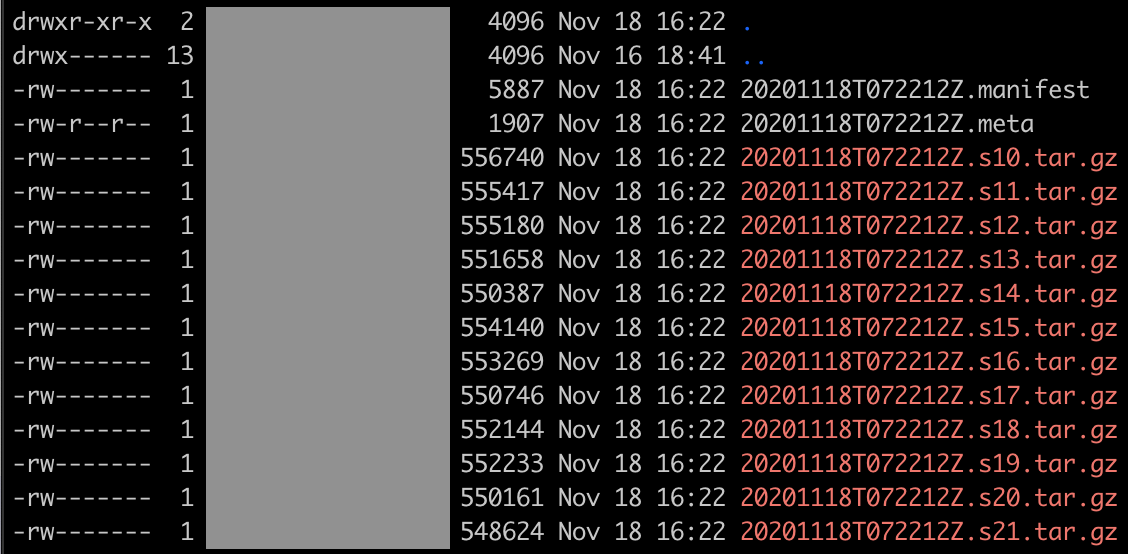
백업#2 - 리모트에서 InfluxDB 백업해보기
리모트에서 InfluxDB 를 백업하기 위해서는 두가지 작업이 필요합니다. 1) 작업을 진행하는 컴퓨터에서 influxd 를 실행할 수 있도록 바이너리가 설치되어 있어야 하며, 2) InfluxDB 장비 설정에 원격지에서 접근을 허용하도록 주소와 포트가 지정되어 있어야 합니다. 우선 2) 번의 작업을 진행해 보겠습니다.
2번의 작업을 위해 InfluxDB 의 설정 파일인 influxdb.conf 를 열겠습니다. 패키지 관리자를 이용하여 설치했다면 아마도 /etc/influxdb/influxdb.conf 정도의 경로에서 설정 파일을 찾아보실 수 있을 겁니다. vim 등의 에디터로 파일을 열고 bind-address 항목을 찾아보도록 하겠습니다. 주석 처리된 부분을 해제하면 기본적으로 서버의 모든 IP 의 지정된 포트로 influxd 가 액세스 할 수 있게 됩니다.
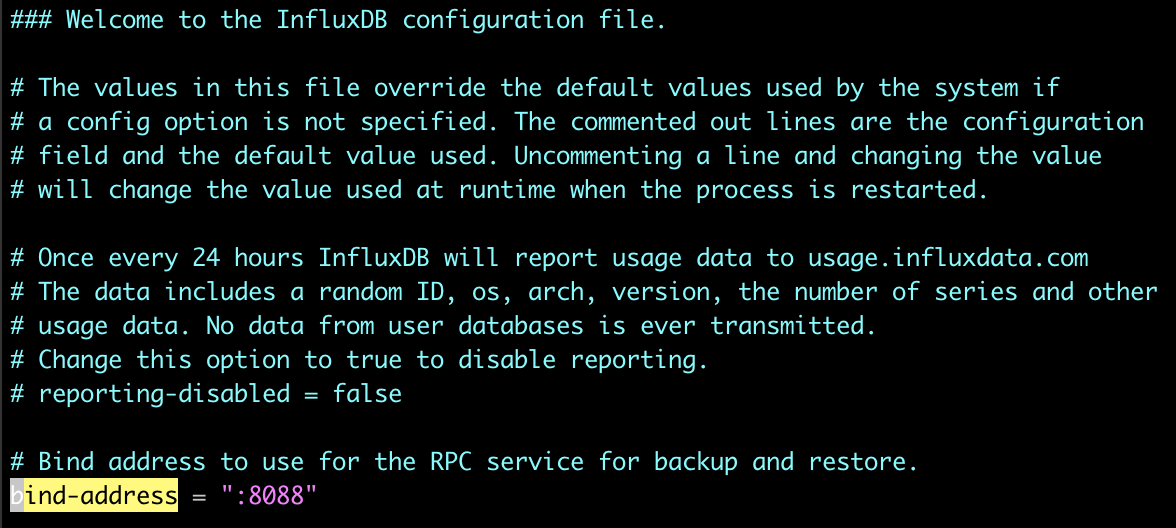
설정이 반영되도록 systemctl restart influxdb.service 명령으로 InfluxDB 를 재기동 하겠습니다. 참고로 InfluxDB 의 기본 포트가 8086 이기 때문에 제어를 위한 HTTP 서비스 포트는 8086 이 아닌 다른 포트를 사용해야 합니다. 공식 문서에서는 8088 포트를 쓰고 있는데 각자의 사정에 맞추어 포트를 지정해주시면 되겠습니다. 참고로 위와 같이 설정하면 서버의 모든 IP 로 8088 번 접근이 가능해집니다.
원격으로 백업 작업을 수행하기 위해서는 -host 옵션을 추가로 지정해 주어야 하고 ##influxdb_IP_주소##:8088 을 지정해 주어야 합니다. 다른 장비에서 아래와 같은 명령으로 8088번 포트로 접근하여 백업을 정상적으로 수행할 수 있었습니다.
[다른장비]$ influxd backup -portable -database myreport -host ##서버주소##:8088 ./
2020/11/18 17:23:48 backing up metastore to meta.00
2020/11/18 17:23:48 backing up db=myreport
2020/11/18 17:23:48 backing up db=myreport rp=autogen shard=3 to myreport.autogen.00003.00 since 0001-01-01T00:00:00Z
2020/11/18 17:23:48 backing up db=myreport rp=autogen shard=4 to myreport.autogen.00004.00 since 0001-01-01T00:00:00Z
...
이번 포스팅에서는 InfluxDB 백업시 알아두어야 할 점과 InfluxDB 가 제공하는 두가지 백업 방법을 살펴보았습니다. 다음 포스팅에서는 이렇게 백업한 파일을 복원하는 방법에 대해서 살펴보겠습니다.
>>> 이어지는 복원 방법 포스팅은 이쪽입니다!
InfluxDB, 데이터의 백업과 복원 #2 / 백업 파일 복원하기
지난 포스팅에 이어 이번 포스팅에서는 백업한 데이터를 복원하는 방법에 대하여 확인해 보도록 하겠습니다. 백업을 위한 파라메터가 `backup` 이었다면 반대로 복원을 위한 파라메터는 `restore`
ondemand.tistory.com

